Краткий курс машинного обучения или как создать нейронную сеть для решения скоринг задачи
Мы часто слышим такие словесные конструкции, как «машинное обучение», «нейронные сети». Эти выражения уже плотно вошли в общественное сознание и чаще всего ассоциируются с распознаванием образов и речи, с генерацией человекоподобного текста. На самом деле алгоритмы машинного обучения могут решать множество различных типов задач, в том числе помогать малому бизнесу, интернет-изданию, да чему угодно. В этой статье я расскажу как создать нейросеть, которая способна решить реальную бизнес-задачу по созданию скоринговой модели. Мы рассмотрим все этапы: от подготовки данных до создания модели и оценки ее качества.
Вопросы, которые разобраны в статье:
• Как собрать и подготовить данные для построения модели?
• Что такое нейронная сеть и как она устроена?
• Как написать свою нейронную сеть с нуля?
• Как правильно обучить нейронную сеть на имеющихся данных?
• Как интерпретировать модель и ее результаты?
• Как корректно оценить качество модели?
Во многих компаниях, менеджеры по продажам общаются с потенциальными клиентами, проводят им демонстрации, рассказывают о продукте. Отдают, так сказать, свою душу по сотому разу на растерзание тем, кто, возможно, попал в их руки совершенно случайно. Часто клиенты недостаточно понимают, что им нужно, или то, что продукт может им дать. Общение с такими клиентами не приносит ни удовольствия, ни прибыли. А самое неприятное то, что из-за ограничения по времени, можно не уделить достаточно внимания действительно важному клиенту и упустить сделку.
Я математик-программист в сервисе seo-аналитики Serpstat. Недавно я получил интересную задачу по улучшению уже существующей и работающей у нас скоринговой модели, по-новому оценив факторы, которые влияют на успех продажи. Скоринг считался на основе анкетирования наших клиентов, и каждый пункт, в зависимости от ответа на вопрос, вносил определенное количество очков в суммарный балл. Все эти баллы за разные вопросы расставлялись на основе статистических гипотез. Скоринговая модель использовалась, время шло, данные собирались и в один прекрасный день попали ко мне. Теперь, когда у меня появилась достаточная выборка, можно было смело строить гипотезы, используя алгоритмы машинного обучения.
Я расскажу вам, как мы построили свою скоринг модель. Это реальный кейс с реальными данными, со всеми трудностями и ограничениями, с которыми мы столкнулись в реальном бизнесе. Итак, обо всем по порядку.
Мы подробно остановимся на всех этапах работы:
▸ Сбор данных
▸ Препроцессинг
▸ Построение модели
▸ Анализ качества и интерпретация модели
Рассмотрим устройство, создание и обучение нейросети. Все это я описываю, решая реальную скоринговую задачу, и постоянно подкрепляю новую теорию примером.
Сбор данных
Вначале нужно понять, какие вопросы будут представлять клиента (или просто объект) в будущей модели. К задаче подходим серьезно, так как на ее основании строится дальнейший процесс. Во-первых, нужно не упустить важные признаки, описывающие объект, во-вторых, создать жесткие критерии для принятия решения о признаке. Основываясь на опыте, я могу выделить три категории вопросов:
- Булевы (бикатегориальные), ответом на которые является: Да или Нет (1 или 0). Например, ответ на вопрос: есть ли у клиента аккаунт?
- Категориальные, ответом на которые является конкретный класс. Обычно классов больше двух (мультикатегориальные), иначе вопрос можно свести к булевому. Например, цвет: красный, зеленый или синий.
- Количественные, ответами на которые являются числа, характеризующее конкретную меру. Например, количество обращений в месяц: пятнадцать.
Зачем я так подробно останавливаюсь на этом? Обычно, когда рассматривают классическую задачу, решаемую алгоритмами машинного обучения, мы имеем дело только с численными данными. Например, распознавание черно-белых рукописных цифр с картинки 20 на 20 пикселей. В этом примере 400 чисел (описывающих яркость черно-белого пикселя) представляют один пример из выборки. В общем случае данные необязательно должны быть числовыми. Дело в том, что при построении модели нужно понимать, с какими типами вопросов алгоритм может иметь дело. Например: дерево принятия решения обучается на всех типах вопросов, а нейросеть принимает только числовые входные данные и обучается лишь на количественных признаках. Означает ли это, что мы должны отказаться от некоторых вопросов в угоду более совершенной модели? Вовсе нет, просто нужно правильно подготовить данные.
Данные должны иметь следующую классическую структуру: вектор признаков для каждого i-го клиента X(i) = {x(i)1, x(i)2, …, x(i)n} и класс Y(i) — категория, показывающая купил он или нет. Например: клиент(3) = {зеленый, горький, 4.14, да} — купил.
Основываясь на вышесказанном, попробуем представить формат данных с типами вопросов, для дальнейшей подготовки:
| класс: (категория) | цвет: (категория) | вкус: (категория) | вес: (число) | твердый: (bool) |
|---|---|---|---|---|
| — | красный | кислый | 4.23 | да |
| — | зеленый | горький | 3.15 | нет |
| + | зеленый | горький | 4.14 | да |
| + | синий | сладкий | 4.38 | нет |
| — | зеленый | соленый | 3.62 | нет |
Таблица 1 — Пример данных обучающей выборки до препроцессинга
Препроцессинг
После того как данные собраны, их необходимо подготовить. Этот этап называется препроцессинг. Основная задача препроцессинга — отображение данных в формат пригодный для обучения модели. Можно выделить три основных манипуляции над данными на этапе препроцессинга:
- Создание векторного пространства признаков, где будут жить примеры обучающей выборки. По сути, это процесс приведения всех данных в числовую форму. Это избавляет нас от категорийных, булевых и прочих не числовых типов.
- Нормализация данных. Процесс, при котором мы добиваемся, например того, чтобы среднее значение каждого признака по всем данным было нулевым, а дисперсия — единичной. Вот самый классический пример нормализации данных: X = (X — μ)/σфункция нормализации
- Изменение размерности векторного пространства. Если векторное пространство признаков слишком велико (миллионы признаков) или мало (менее десятка), то можно применить методы повышения или понижения размерности пространства:
- Для повышения размерности можно использовать часть обучающей выборки как опорные точки, добавив в вектор признаков расстояние до этих точек. Этот метод часто приводит к тому, что в пространствах более высокой размерности множества становятся линейно разделимыми, и это упрощает задачу классификации.
- Для понижения размерности чаще всего используют PCA. Основная задача метода главных компонент — поиск новых линейных комбинаций признаков, вдоль которых максимизируется дисперсия значений проекций элементов обучающей выборки.
Одним из важнейших трюков в построении векторного пространства является метод представления в виде числа категориальных и булевых типов. Встречайте: One-Hot (рус. Унитарный Код). Основная идея такой кодировки — это представление категориального признака, как вектора в векторном пространстве размерностью, соответствующей количеству возможных категорий. При этом значение координаты этой категории берется за единицу, а все остальные координаты обнуляются. С булевыми значениями все совсем просто, они превращаются в вещественные единицы или нули.
Например, элемент выборки может быть или горьким, или сладким, или соленым, или кислым, или умами (мясным). Тогда One-Hot кодировка будет следующей: горький = (1, 0, 0, 0 ,0), сладкий = (0, 1, 0, 0 ,0), соленый = (0, 0, 1, 0 ,0), кислый = (0, 0, 0, 1 ,0), умами = (0, 0, 0, 0, 1). Если у вас возник вопрос почему вкусов пять, а не четыре, то ознакомьтесь с этой статьей о вкусовой сенсорной системе, ну а к скорингу это никакого отношения не имеет, и мы будем использовать четыре, ограничившись старой классификацией.
Теперь мы научились превращать категориальные признаки в обычные числовые вектора, а это очень полезно. Проведя все манипуляции над данными, мы получим обучающую выборку, подходящую любой модели. В нашем случае, после применения унитарной кодировки и нормализации данные выглядят так:
| class: | red: | green: | blue: | bitter: | sweet: | salti: | sour: | weight: | solid: |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0.23 | 1 |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | -0.85 | 0 |
| 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0.14 | 1 |
| 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0.38 | 0 |
| 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | -0.48 | 0 |
Таблица 2 — Пример данных обучающей выборки после препроцессинга
Можно сказать, что препроцессинг — это процесс отображения понятных нам данных в менее удобную для человека, но зато в излюбленную машинами форму.
Формула скоринга чаще всего представляет из себя следующую линейную модель:
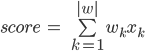
Где, k — это номер вопроса в анкете, wk — коэффициент вклада ответа на этот k-ый вопрос в суммарный скоринг, |w| — количество вопросов (или коэффициентов), xk — ответ на этот вопрос. При этом вопросы могут быть любыми, как мы и обсуждали: булевыми(да или нет, 1 или 0), числовыми (например, рост = 175) или категориальными, но представленными в виде унитарной кодировки (зеленый из перечня: красный, зеленый или синий = [0, 1, 0]). При этом можно считать, что категориальные вопросы распадаются на столько булевых, сколько категорий присутствует в вариантах ответа (например: клиент красный? клиент зеленый? клиент синий?).
Выбор модели
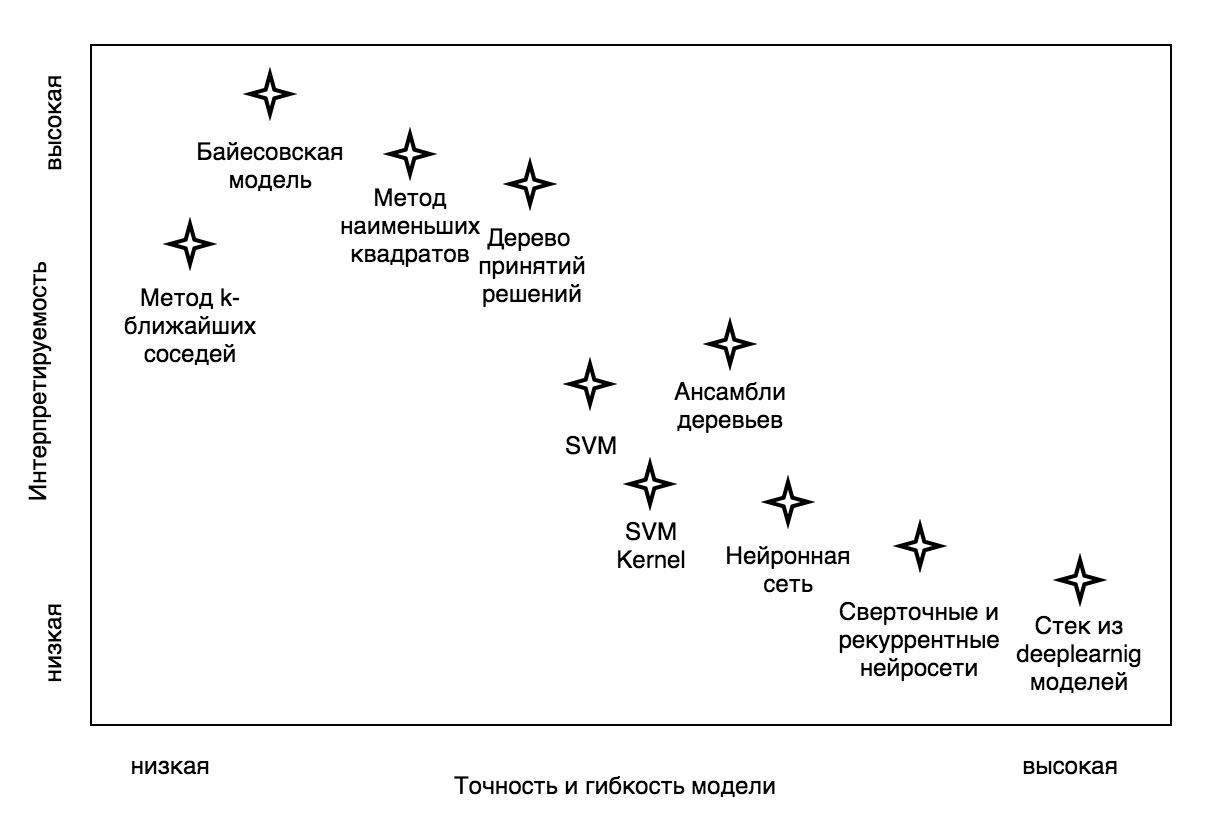
Теперь самое важное: выбор модели. На сегодняшний день существует множество алгоритмов машинного обучения, на основе которых можно построить скоринг модель: Decision Tree (дерево принятия решений), KNN (метод k-ближайших соседей), SVM (метод опорных векторов), NN (нейросеть). И выбор модели стоит основывать на том, чего мы от нее хотим. Во-первых, насколько решения, повлиявшие на результаты модели, должны быть понятными. Другими словами, насколько нам важно иметь возможность интерпретировать структуру модели.
Кроме того, не все модели легко построить, для некоторых требуются весьма специфические навыки и очень-очень мощное железо. Но самое важное — это внедрение построенной модели. Бывает так, что бизнес-процесс уже налажен, и внедрение какой-то сложной модели попросту невозможно. Или требуется именно линейная модель, в которой клиенты, отвечая на вопросы, получают положительные или отрицательные баллы в зависимости от варианта ответа. Иногда, напротив, есть возможность внедрения, и даже требуется сложная модель, учитывающая очень неочевидные сочетания входных параметров, находящая взаимосвязи между ними. Итак, что же выбрать?
В выборе алгоритма машинного обучения мы остановились на нейронной сети. Почему? Во-первых, сейчас существует много крутых фреймворков, таких как TensorFlow, Theano. Они дают возможность очень глубоко и серьезно настраивать архитектуру и параметры обучения. Во-вторых, возможность менять устройство модели от однослойной нейронной сети, которая, кстати, неплохо интерпретируема, до многослойной, обладающей отличной способностью находить нелинейные зависимости, меняя при этом всего пару строчек кода. К тому же, обученную однослойную нейросеть можно превратить в классическую аддитивную скоринг модель, складывающую баллы за ответы на разные вопросы анкетирования, но об этом чуть позже.
Теперь немного теории. Если для вас такие вещи, как нейрон, функция активации, функция потери, градиентный спуск и метод обратного распространения ошибки — родные слова, то можете смело это все пропускать. Если нет, добро пожаловать в краткий курс искусственных нейросетей.