
Автоматизация машинного обучения с помощью DevOps для MATLAB и Simulink
Поскольку все больше организаций полагаются на приложения машинного обучения для выполнения основных бизнес-функций, многие из них уделяют больше внимания полному жизненному циклу этих приложений. Первоначальное внимание к разработке и развертыванию моделей машинного обучения было расширено за счет непрерывного мониторинга и обновлений. Изменения во входных данных могут снизить точность предсказания или классификации модели. Своевременное переобучение и оценка моделей позволяют получать более качественные модели и принимать более точные решения.
В операциях машинного обучения, или ML Ops, действия по планированию, проектированию, сборке и тестированию связаны с развертыванием, эксплуатацией и мониторингом операций в непрерывном цикле обратной связи (рис. 1). Многие команды специалистов по данным начали автоматизировать части цикла ML Ops, такие как развертывание и операции.
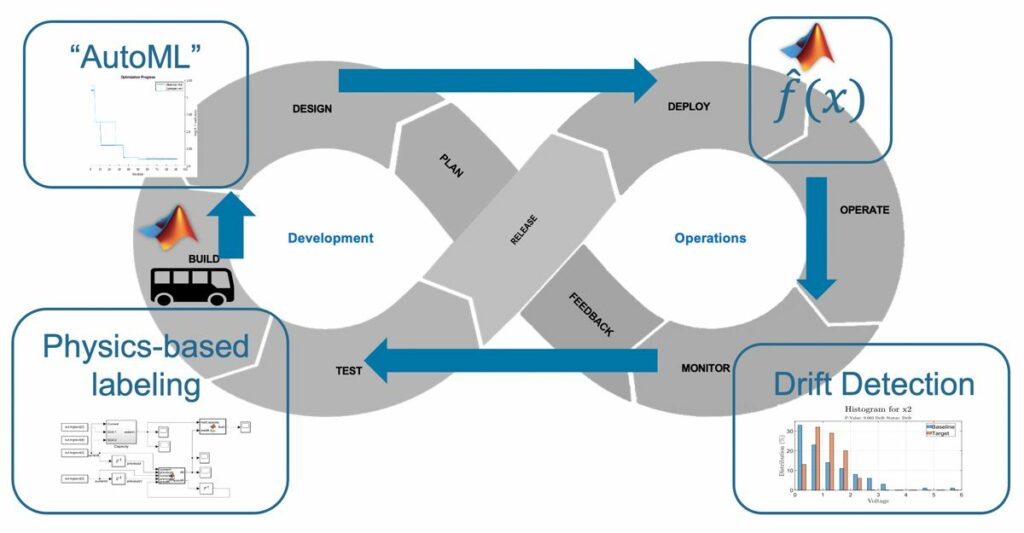
Однако для полной автоматизации цикла требуются дополнительные шаги: мониторинг и оценка производительности модели, включение результатов этой оценки в более производительную модель и повторное развертывание новой модели. Внедрение этой автоматизации дает значительные преимущества, позволяя специалистам по данным тратить больше времени на разработку полезных решений машинного обучения и меньше времени на ИТ-администрирование и утомительные, подверженные ошибкам ручные задачи.
Чтобы проиллюстрировать, как модельно-ориентированное проектирование с MATLAB® и Simulink® можно использовать для автоматизации процессов ML Ops, мы внедрили приложение для профилактического обслуживания вымышленной городской транспортной системы. Организации нужен был способ планировать техническое обслуживание или замену аккумуляторов в своем парке электробусов до того, как возникнет риск выхода аккумуляторов из строя во время движения.
Приложение включает в себя модель машинного обучения, которая использует состояние заряда батареи (SOC), ток и другие измерения для прогнозирования состояния батареи (SOH). Другие компоненты включают в себя сервер приложений, который запускает модель машинного обучения в масштабе, компонент обнаружения дрейфа, который сравнивает наблюдаемые данные с обучающими данными, чтобы определить, когда требуется повторное обучение, и высокоточную физическую модель батареи, которая позволяет автоматически маркировать наблюдаемые данные. .
Для многих организаций этот последний компонент — высокоточная физическая модель — является недостающим компонентом, обеспечивающим полную автоматизацию. Без этого человек необходим для просмотра наблюдаемых данных и применения меток; с его помощью можно автоматизировать этот фундаментальный этап и весь цикл ML Ops.
Построение моделей для генерации данных о батареях и автоматической маркировки
Прежде чем мы смогли начать обучение модели машинного обучения для прогнозирования состояния батареи, нам нужны были данные. В некоторых случаях в организации может быть много данных, собранных из действующих систем реального мира. В других, в том числе для нашей вымышленной транспортной системы, данные должны генерироваться с помощью моделирования.
Чтобы сгенерировать обучающие данные для аккумуляторной системы транспортной сети, мы создали две модели, основанные на физике, с помощью Simulink и Simscape™. Первая модель, включающая динамику из электрической и тепловой областей, генерирует реалистичные необработанные измерения датчика, включая ток, напряжение, температуру и SOC (рис. 2). Второй вычисляет SOH на основе предполагаемой емкости батареи и внутреннего сопротивления, которые получены из измерений, произведенных первой моделью. Именно эта вторая модель позволяет нам автоматически маркировать наблюдаемые данные и резко снизить потребность в человеческом вмешательстве в цикл переобучения.
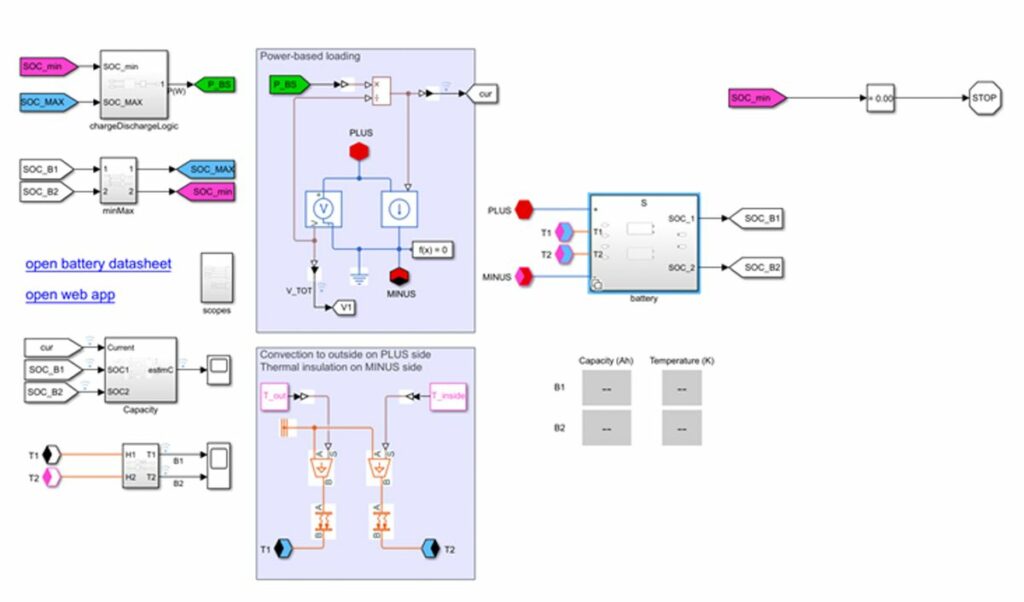
Применяя независимые профили старения к отдельным батареям и изменяя входную температуру окружающей среды для первой модели, мы создали набор исторических данных для большого парка транспортных средств, подходящий для обучения нашей модели машинного обучения для профилактического обслуживания.
Создание и развертывание модели машинного обучения
Получив данные для обучения, мы обратили внимание на модель машинного обучения. Мы использовали приложение Diagnostic Feature Designer для изучения необработанных измерений, извлечения многодоменных признаков и выбора набора признаков с лучшими индикаторами состояния. Поскольку нашей целью была автоматизация всего цикла, нам также необходимо было автоматизировать выбор модели и ее обучение. С этой целью мы создали компонент, который мы называем AutoML. Этот компонент, встроенный в MATLAB со Statistics and Machine Learning Toolbox™, отвечает за автоматический поиск лучшей модели машинного обучения и оптимальных гиперпараметров для заданного набора обучающих данных. Компонент AutoML также запускает цикл: он создает нашу начальную модель машинного обучения на основе исходных обучающих данных и нашего набора функций.
В дополнение к машинам опорных векторов компонент AutoML обучает и оценивает модели линейной регрессии, модели регрессии гауссовского процесса, ансамбли усиленных деревьев решений, случайные леса и полностью связанные нейронные сети с прямой связью (рис. 3). Компонент AutoML использует MATLAB Parallel Server™ для ускорения этой части процесса за счет одновременного обучения и оценки нескольких моделей.
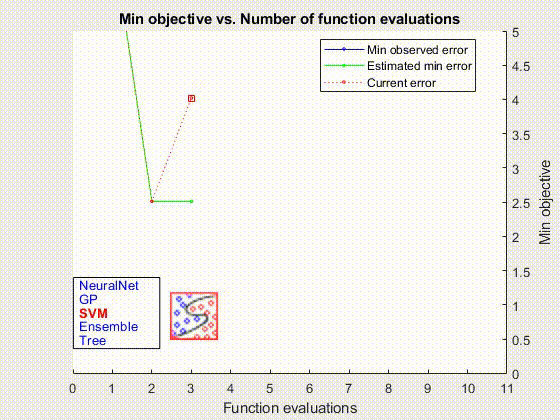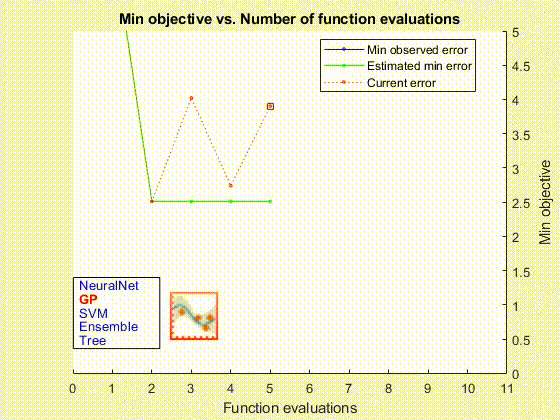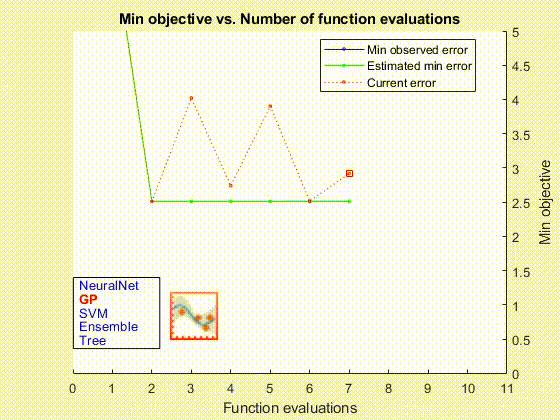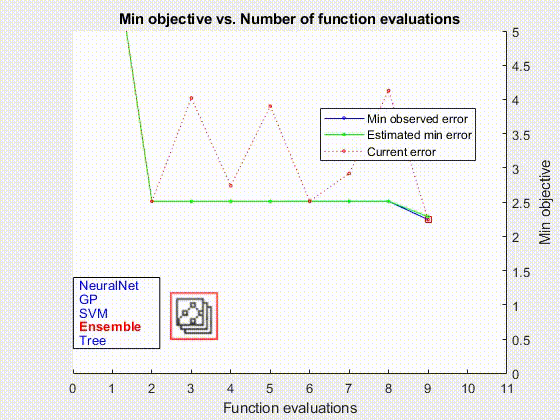
Когда процесс AutoML был завершен, мы развернули оптимальную модель в нашей локальной производственной среде с помощью MATLAB Production Server™.
Выявление и устранение дрейфа данных
Во многих задачах машинного обучения существует неявное предположение, что данные, используемые для обучения модели, полностью представляют базовое распределение всего пространства признаков. Другими словами, предполагается, что распределение данных не меняется. В реальном мире это не всегда так. Например, в нашем приложении для электрического автобуса мы могли обучить нашу модель с предположением, что транспортные средства будут работать в определенном диапазоне температур. Однако в производстве мы обнаруживаем, что автобусы часто работают при температурах выше этого диапазона. Это изменение данных называется дрейфом, и по мере увеличения дрейфа точность прогнозов, сделанных моделью, имеет тенденцию к снижению. Поэтому специалистам по данным часто необходимо обнаруживать изменения в данных, которые развиваются с течением времени, и реагировать на них, как правило, путем обучения новых моделей.
Здесь важно различать дрейф концепции и дрейф данных. В машинном обучении дрейф концепции определяется как изменение совместной вероятности наблюдаемых функций и меток или ответов с течением времени. Может быть довольно сложно использовать дрейф концепции для моделей машинного обучения в производственной среде, поскольку необходимо знать как значения функций, так и значения ответов. В результате многие организации сосредотачиваются на следующем лучшем варианте: дрейф данных или изменение распределения только наблюдаемых признаков, а не меток. Это подход, который мы использовали.
Мы разработали приложение MATLAB для обнаружения дрейфа, которое сравнивает значения в новых наблюдаемых данных со значениями в обучающем наборе модели.
В рабочей среде он считывает наблюдаемые данные практически в реальном времени из потока Apache® Kafka и делает прогнозы состояния батареи с помощью функции MATLAB, которая обрабатывает наблюдения с использованием нашей модели машинного обучения (рис. 4). Мы разработали эту функцию MATLAB с использованием Streaming Data Framework для MATLAB Production Server, что позволило нам легко перейти от обработки исторических данных в файлах к оперативным данным в потоках Kafka. Фреймворк обрабатывает потоковые данные через серию итераций, потому что весь поток не помещается в память. Каждая итерация состоит из четырех шагов: прочитать пакет наблюдений из потока, загрузить модель, сделать прогноз и записать его в выходной поток и, при необходимости, сохранить любые данные, необходимые для следующей итерации. Размер каждого пакета охватывает временной интервал, достаточный для того, чтобы извлеченные функции отображали достаточные характеристики батареи для достоверного прогноза SOH.
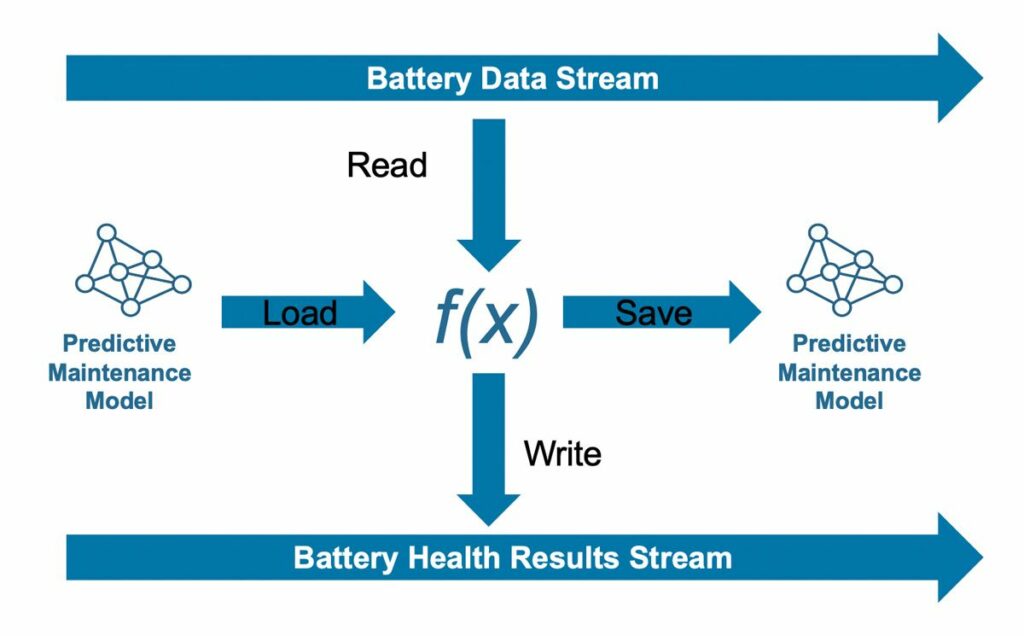
Обратите внимание, что даже если приложение обнаружения дрейфа определяет, что в наблюдаемых данных произошли значительные изменения, это не обязательно означает, что модель машинного обучения устарела. Приложение не может определить, устарела ли модель, пока не получит значения отклика (или метки) для новых наблюдаемых данных, что оно делает, распространяя новые данные через основанную на физике модель SOH. В этот момент приложение может сравнить значения отклика из модели, основанной на физике, со значениями отклика из модели машинного обучения; если значения значительно различаются, пришло время вызвать компонент Auto ML с новыми данными и автоматически создать новую модель машинного обучения, оптимизированную для данных, которые сейчас поступают от парка.
Справедливо спросить, зачем нам нужна модель машинного обучения для прогнозирования состояния батареи, если мы можем оценить его с помощью моделирования в первую очередь. Ответ заключается в том, что модель машинного обучения может генерировать прогнозы практически в реальном времени — намного быстрее, чем это возможно с помощью моделирования на основе физики.
Масштабируемая универсальная архитектура
Мы разработали архитектуру для автоматизации ML Ops с возможностью горизонтального масштабирования. Компоненты прогнозирования и мониторинга работают на MATLAB Production Server, а обучение модели выполняется на MATLAB Parallel Server (рис. 5). Архитектура также универсальна. Хотя в нашем примере основное внимание уделялось диагностическому обслуживанию и обнаружению дрейфа электрических автобусов, архитектуру можно легко адаптировать к другим приложениям и вариантам использования. Например, модель Simulink, основанную на физике, можно заменить численной моделью, разработанной в MATLAB. Точно так же многие из используемых нами готовых компонентов, таких как Apache Kafka для потоковой передачи данных, Grafana для платформы панели мониторинга, можно заменить другими облачными сервисами.
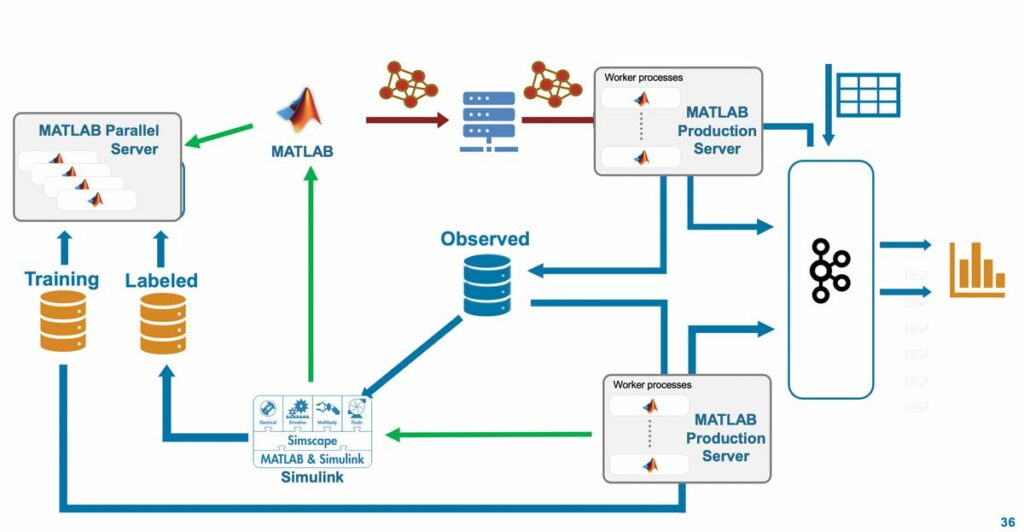
Использование готовых компонентов позволило нам сосредоточиться на архитектуре, а не на деталях реализации, подобно тому, как полностью автоматизированный цикл ML Ops позволяет специалистам по данным сосредоточиться на разработке решений для машинного обучения, а не на управлении деталями ИТ-администрирования.